For the following Ranksense Webinar, we were joined by Antoine Eripret, who works at Liligo as an SEO lead. Liligo.com is a travel search engine which instantly searches all available flight, bus and train prices on an exhaustive number of travel sites such as online travel agencies, major and low-cost airlines and tour-operators. In this Ranksense Twittorial webinar, Antoine takes us on his journey of discovering SEO from a non-engineering background. Having a lot of experience in leveraging Python skills to automate repetitive SEO tasks, Antoine demonstrates how one can find content gaps at scale between two websites.
Here is a full recording of the webinar:
https://youtu.be/07PD48ViScU
During this webinar, Antoine aims to teach how to leverage Python to compare different websites and services and detect content gaps at scale.
Antoine Eripret Background and SEO Journey
Having studied in Lille, a city in the north of France and close to Belgium, Antoine has a background in marketing. In Barcelona, Antoine interned at a marketing start-up where they researched email and paid marketing in the form of advertisements, social media and SEO. This was Antoine’s first exposure to SEO. After that, Antoine returned back to France to continue his studies. Antoine realized his passion was to develop his skills further in SEO and make a career in that.
Doing projects with e-commerce, SEO, B2B, etc., Antoine learned about SEO and has been developing his skills since 2016. While working at a digital agency in Barcelona, Antoine soon realized that the SEO tasks that he was doing were very repetitive with monotonous working hours. This made him pursue a method of automating the tasks that were common between all projects (such as data gathering, presentation, extraction, etc.). In his investigation, Antoine stumbled onto Python and started reading books on automation. Antoine still enjoys continuing the journey of learning new things, putting an effort to always stay updated on the new trends.
Is Python even necessary?
Hamlet asked Antoine why he stopped using Excel, as he could do the same things in Excel that he did with Python. Antoine explained that for files with humongous amounts of data, one has to essentially parse an entire Excel file every time they want to extract meaningful data from it. Python is really useful for parameterizing the automation, which allows us to save time, scale the operations, share it with other people, replicate the processes, etc.
Coming from a non-engineering background, Antoine initially gave up on learning Python, as it was too daunting for him. After watching Robin Lord’s presentation on Python replacing Excel combined with his own experience of hitting the limits of data management, Antoine started learning Python again. This time, following a proper training curriculum, Antoine was able to come up with his own solutions to the problems at his agency.
Walking Through The Presentation
If you want to take a quick look at Antoine’s script before we go through it, you can find it here.
Whatever travel website you use, at the end of the day, it is all about selling the journey. Different websites might have different structures but all of them can only sell you the journey. This similarity between the websites makes it so that anything that is slightly different stands out in comparison.
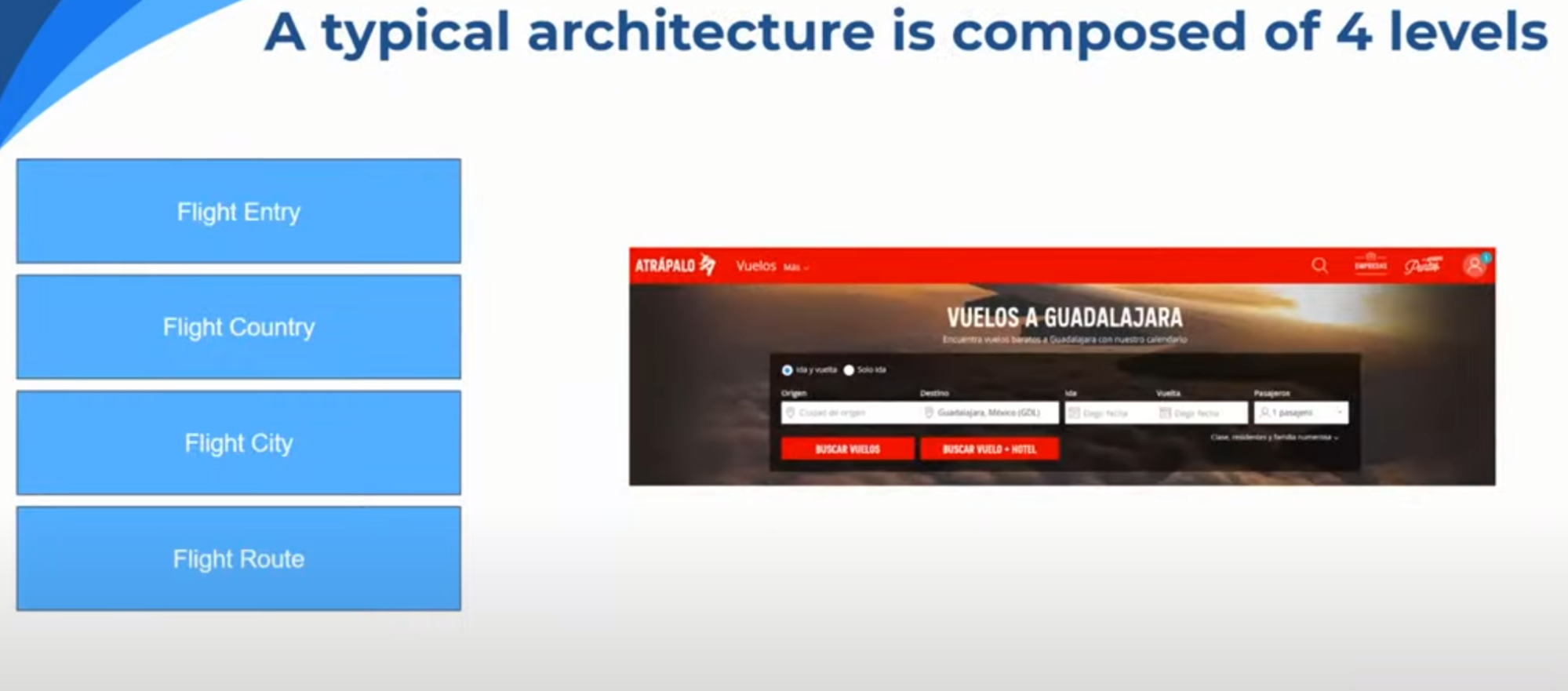
Antoine explains that a typical website architecture for a flight travel website includes at least 4 levels. The basic level is the Flight Entry, where you see flights on the page for the website. Flight country is a page to target queries around a specific country, e.g. flight to France. Flight City and Flight Route go hand in hand since the former gives you a page to target queries around a specific city and the latter gives you different routes from and to a city, for example, direct routes or connecting flights. Antoine also emphasizes that Flight Routes is the most important level out of these.
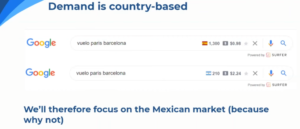
Antoine emphasizes on the fact that Demand is based on country. When Antoine is in Barcelona and searches for flights, he sees that Spain has higher results than Argentina. This is because the search engine will prioritize results for Spain for users in Barcelona. This is due to the fact that the architecture of a website heavily depends on its host country.
Objective for the Comparison

Before proceeding, Antoine explains why you cannot compare the number of results from two websites at face value. Here, face value would mean the amount of URLs that are returned when you Google Search the two sites. Antoine’s search for Atrapalo returned about 5,000 results whereas Skyscanner returned about 17,000 results. One might think that Atrapalo is not as popular as Skyscanner, or that the SEO for Skyscanner is just better. However, Antoine emphasizes how you cannot rank on a query you don’t have content for. For example, if I run two parallel searches here in New Jersey:
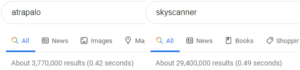
One can see that the difference now is humongous. However, a comparison can only be made when the content you are comparing is relevant and on fair ground. Search city, flight paths, flight entries, country search engine, region statistics, hourly traffic, etc., are some of the factors that are taken into account when considering relevant queries.
Therefore for an objective comparison this is the scenario that we are going to assume for the rest of the workshop: We are working for Atrapalo in Mexico and we want to have a close look at what Skyscanner is doing. One of the hypotheses we want to test is that they are ranking and performing well on some queries where we don’t even have a page created.
Setting up the Tools

Antoine chooses Python and Google Colab as his tools to run the compare the two websites. Colab is a hosted Jupyter notebook service. It allows anybody to write and execute arbitrary python code through the browser. The primary goal is to detect content gaps at scale. Antoine chooses Colab as it is easy to share code, even if Python or Jupyter Notebooks are not installed. Next up is the libraries:
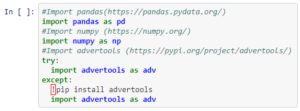
Antoine starts by importing three libraries important to extract, manipulate and demonstrate the huge amounts of data from airliner datasets. The import command imports libraries from other people’s codes. The try and except basically tries to import the advertools library if it is already installed on your local machine. However, if it is not, it first installs the library and then imports it. The ! makes the ipynb (the Jupyter notebook) run a shell command, which in this case is the pip install advertools. If you were not using Jupyter or Colab, you would run this in a shell like cmd or powershell. In that case, click the windows button and type ‘cmd’ and press enter. Once you do that type pip install advertools. This will achieve the same effect; you will be successfully able to import advertools in the text editor/IDE of your choosing.
Extract and Filter Data

Antoine then begins his script by loading the sitemaps. For now, he is not going to crawl the entire sitemap. He will use them to get a list of URLs. To load the sitemaps, Antoine runs the adv.sitemap_to_df function, which is a method to transform a sitemap(or a sitemap index) to a DataFrame (a pandas feature; referred to as df). This returns the sitemap of the websites as a data frame. The robots.txt file usually provides the argument for the sitemap URL.
Antoine then prints the number of rows and columns returned for both sitemaps.
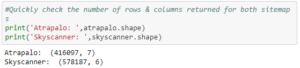
In this case, Antoine chooses not to crawl the website. This is because he doesn’t need to look at the content of the website. Crawling is useful to look for titles, h1 tags, meta descriptions, internal linking, etc., but that information is not needed for this exercise. Therefore, Antoine chooses to convert the sitemap of the website into a DataFrame.
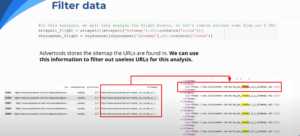
Importing the sitemaps as DataFrames resulted in a huge amount of rows and columns. The rows for both Atrapalo and Skyscanner amount to a total of about a million rows. However, since we are only concerned with the Flight Route sub-level of the website architecture, we can filter all the useless data, data that includes information about Flight Entries, Flight Countries, Flight Cities and other website data. The way Antoine does is by using a function of string called str.contains(‘route’) to filter out everything that does not contain the word route. This will extract data that pertains to Flight Route pages. Then Antoine creates a new dataframe of only the Flight Route pages. Antoine then checks the size of the updated DataFrame with the shape function:
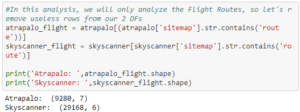
This tells us that the amount of URLs strictly concerning Flight Route for Atrapalo and Skyscanner in their sitemaps, is 2.23% and 5.044% respectively. This means that the Flight Route data that Skyscanner has is about double that of Atrapalo. While this does not directly correlate to the Google search, it gives us critical insight on why Skyscanner appears to be more popular.
Matching Flight Routes
At the end of the day, we want useful data, not just any data. Concerning SEO, the primary goal is to have content that can rank, index and ultimately generate revenue. So we have the Flight Route data for both Atrapalo and Skyscanner, and keeping our goal of comparing both the websites in mind, we can run a matching function that will match the flight routes Skyscanner has that Atrapalo does not.
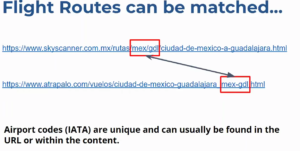
One can do that by comparing the appended DataFrames themselves. This is done by matching the Airport codes (IATA), the international standard of assigning unique three letter codes that designate many airports and metropolitan areas around the world. You can easily find this int he website URLs. It is advantageous that this data is in the URL. This means you can match the data by accessing the URL itself and don’t have to crawl everything.
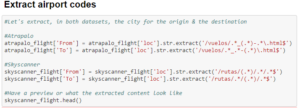
Since we have all the data we need, we just need to extract it now. Antoine defines the from and to data sets. These can be used to store data from the URLs of Atrapalo and Skyscanner data sets(stored as strings). This results in a really condensed and filtered data set, useful for extracting meaningful data. The str.extract function extracts all strings that contain that particular argument, which is /vuelos/.*_(.*)-.*\.html$
For someone who wants to extract data from different websites and does not know how to, you can visit Regex101 to test strings. Once you find the string regular expression that works for you, you can copy and paste it in the parenthesis of the str.extract(‘paste _here’) function. Returning skyscanner_flight.head() gives us a preview of the dataframe. We now have a much filtered and compact data set with us. Now that we have the two key elements of the data, the origin and the destination airport, we can build a full route by appending them.
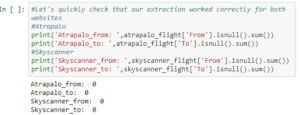
Antoine then prints the values for the origin and destination airports for Atrapalo and Skyscanner datasets. This makes sure that the extraction worked successfully. We can now append this data to create a matching ID.

Antoine then proceeds to build the full route by appending the data by adding the atrapalo_flight[‘From’] and atrapalo_flight[‘To’] to the atrapalo_flight[‘Route’]. Remember that atrapalo_flight is a data set (it can be visualized like a tabular data array), and atrapalo_flight[] lets us access the [route, to, from, etc.] part of the data frame.

Antoine then finds the fraction of routes that Skyscanner has that Atrapalo does not. He achieves this by dividing the extra Skyscanner routes by the total amount of skyscanner flights. The extra Skyscanner routes are the amount of its flight routes that do not appear in Atrapalo flight routes. This basically translates to 1 – the amount of flights only in Atrapalo. This number comes out to be about 0.95. Around 95% of Skyscanner’s flight routes don’t exist on Atrapalo. It is quite huge but we know that foreign routes may not have a huge demand in Mexico. Our goal is therefore to find valuable routes that we must create if we don’t have them yet.
Loading SEMrush data and Finalizing the Results
To get traffic data, Antoine uses SEMrush, an online tool suite that has detailed SEO data for websites.
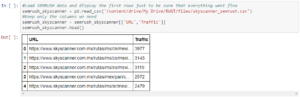
Antoine displays the first rows to make sure everything is fine by reading the .csv file from SEMrush for Skyscanner. He creates a new filtered data frame that only includes the URL and the traffic for that URL. This results in a tabular data set that includes serialized entries. SEMrush thus is useful for monitoring and analyzing the traffic data.
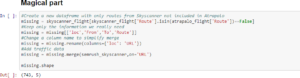
Finally, Antoine creates a new data frame that includes all the routes from Skyscanner that are not in Atrapalo. He names it missing since the scenario is that he is working for Atrapalo, so the data in Skyscanner that is not in Atrapalo is all the missing data. Since the only useful data is the loc, From, To and Route, because they are the aspects of the Flight Route architecture of the website, they are the only categories in the data frame. Antoine then proceeds to merge the SEMrush data with the missing data frame loc column, which is aptly renamed to URL for easier readability. Out of the routes Antoine identified as missing, only 788 seem to rank on a keyword (based on SEMrush data). Antoine finalizes by cleaning the results and sorting the values to present a more readable data frame.
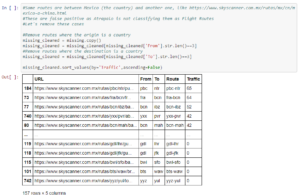
Antoine emphasizes that due different classification techniques, Atrapalo has many false positives. Skyscanner includes routes where the origin or destination is a country rather than a city. Thus, it will show the results for all airports in that country. However, Atrapalo does not use countries as an origin or destination, only cities. In order to remove the data for these country-based routes, Antoine first starts out by making a copy of the data frame and calls it missing_cleaned.
Then he removes the routes where the origin or the destination are countries, by overwriting the data for the missing_cleaned copy. Lastly, Antoine sorts this by traffic amount and returns the data frame. The result is a filtered data set with all Flight Routes included in Atrapalo’s database but not in Skyscanner’s database. Looking at the IATA airport codes sorted by traffic, there definitely are people buying flights from Mexico when they plan European trips. Antoine also briefly suggests the idea of exploring the search volume to confirm this theory.

Antoine ends the presentation by saving the output file as a .csv file that can be shared with colleagues.
Closing Remarks
Once again, we would like to thank Antoine Eripret for the informative presentation about detecting content gaps at scale. If you would like to contact him, you can do so on Twitter. Antoine’s script and notes are on the Ranksense GitHub for anyone to leave questions or suggestions. Be sure to visit @RankSense on Twitter for new updates on upcoming events.